Feature-Aligned Speech Watermarking for Robustness to Reconstruction Distortions
Abstract
Audio watermarking aims to embed identifiable information into audio while remaining imperceptible. Existing methods adopt high-fidelity, low-energy designs to preserve perceptual quality, but the resulting watermarks lack robustness under suppression by speech reconstruction models. Improving robustness is challenging due to the inherent robustness-fidelity trade-off in existing designs, where increasing watermark energy improves robustness but reduces fidelity. To address this problem, we propose a feature-aligned watermarking method that aligns the watermark with the original speech feature distribution, allowing higher watermark energy to improve robustness while preserving imperceptibility. We use a pretrained speech codec to generate a pseudo-speech watermark and fuse it into the spectrogram of the input audio, with VAD loss and perceptual losses guiding embedding within voiced regions. Experiments show that our method maintains imperceptibility comparable to existing approaches while substantially improving robustness under both seen and unseen speech reconstruction models.
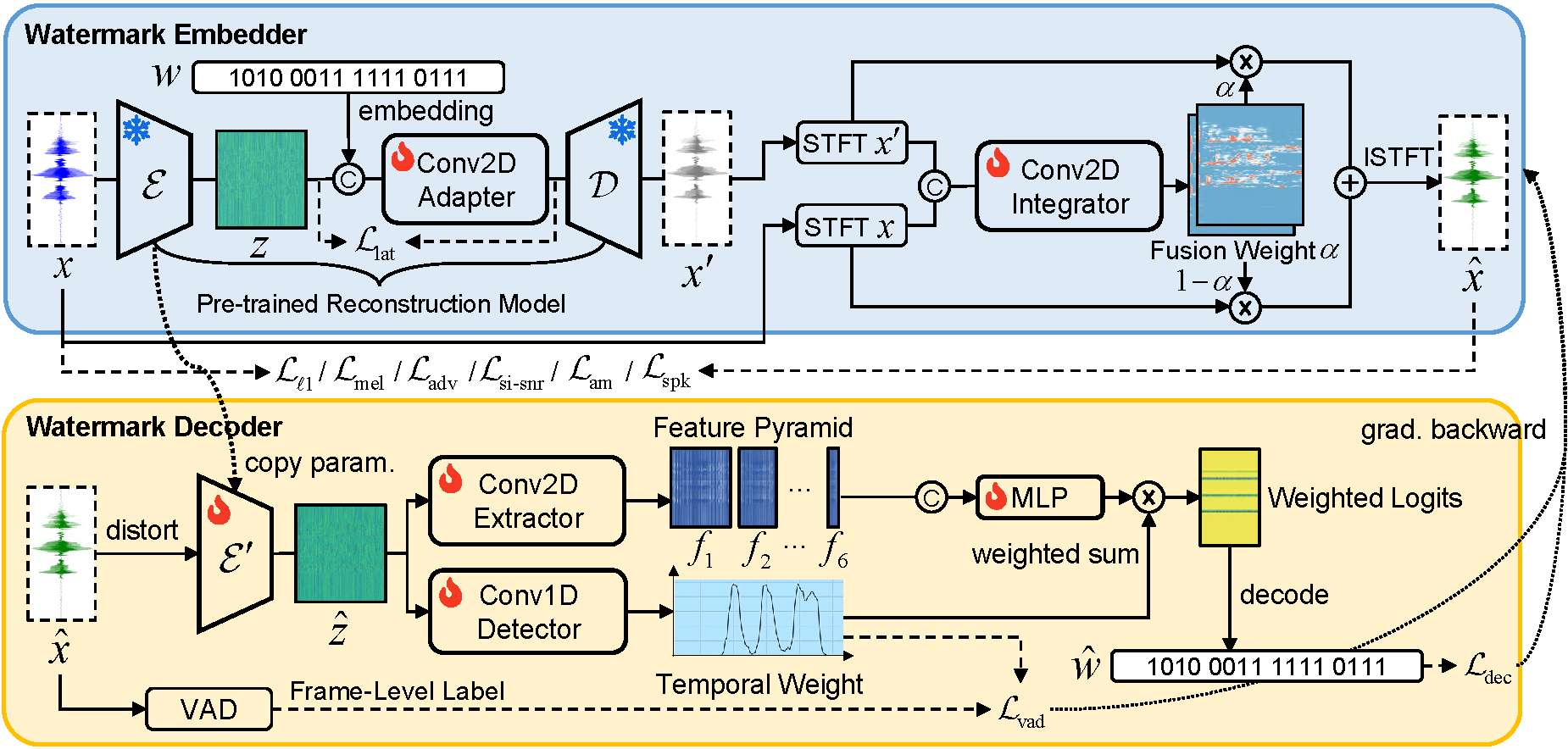
Method Overview
Ours embeds the watermark in pretrained codec latents to produce a pseudo-speech watermark whose feature distribution is close to the original speech.
A spectrogram-domain integrator then fuses the pseudo-speech watermark into voiced regions, guided by VAD, perceptual, and decoding losses. This alignment lets the watermark carry more recoverable energy while preserving perceptual transparency.
Watermarking Examples
Compare the original audio with WavMark, AudioSeal, TimbreWM, VoiceMark, WMCodec, and Ours outputs across LibriSpeech, LJSpeech, and VCTK.
| Sample | Original | WavMark | AudioSeal | TimbreWM | VoiceMark | WMCodec | Ours |
|---|